Le 19 décembre 2022
Pour progresser dans l’utilisation d’un logiciel, il y a 2 possibilités :

Nous vous proposons 10 bonnes pratiques issues de notre expérience, et indirectement de celle de tous nos clients utilisant la solution DriveWorks depuis plus de 15 ans. Les outils DriveWorks suivent une philosophie très similaire aux produits Dassault Systèmes SOLIDWORKS. Ils sont donc extrêmement souples et laissent à l’utilisateur une très grande liberté.Comme souvent, lorsqu’on est libre, rien ne nous empêche de faire des choix qui peuvent être inadaptés et finalement avoir des inconvénients majeurs qui n’avaient pas été anticipés.
Ces 10 bonnes pratiques vous éviteront de perdre du temps en commettant à votre tour les erreurs que d’autres ont déjà expérimentées et solutionnées pour vous !
S’il est possible d’organiser librement les fichiers qui composent un groupe DriveWorks, certains choix pourraient être préjudiciables.
Pour commencer, il y a 2 types de groupes : individuels (Individual) et partagés (Shared)
Pour lever cette limitation, les groupes partagés stockent leurs informations dans une base de données sur un server Microsoft SQL.
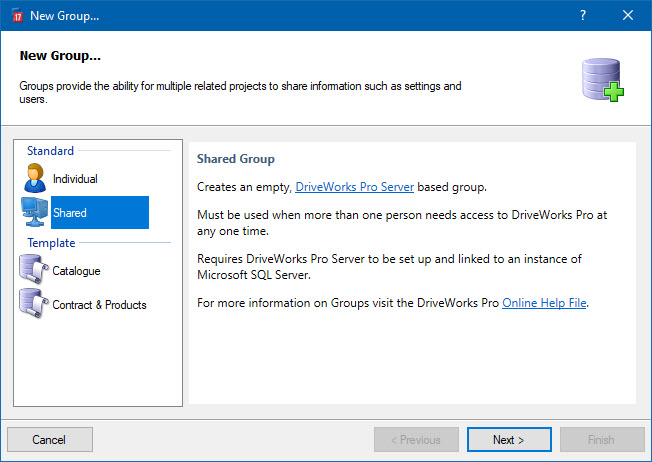
En plus de ces données, d’autres fichiers sont nécessaires au fonctionnement des configurateurs.
Tous ces fichiers devront idéalement être stockés et organisés dans le dossier du groupe DriveWorks de la manière suivante :
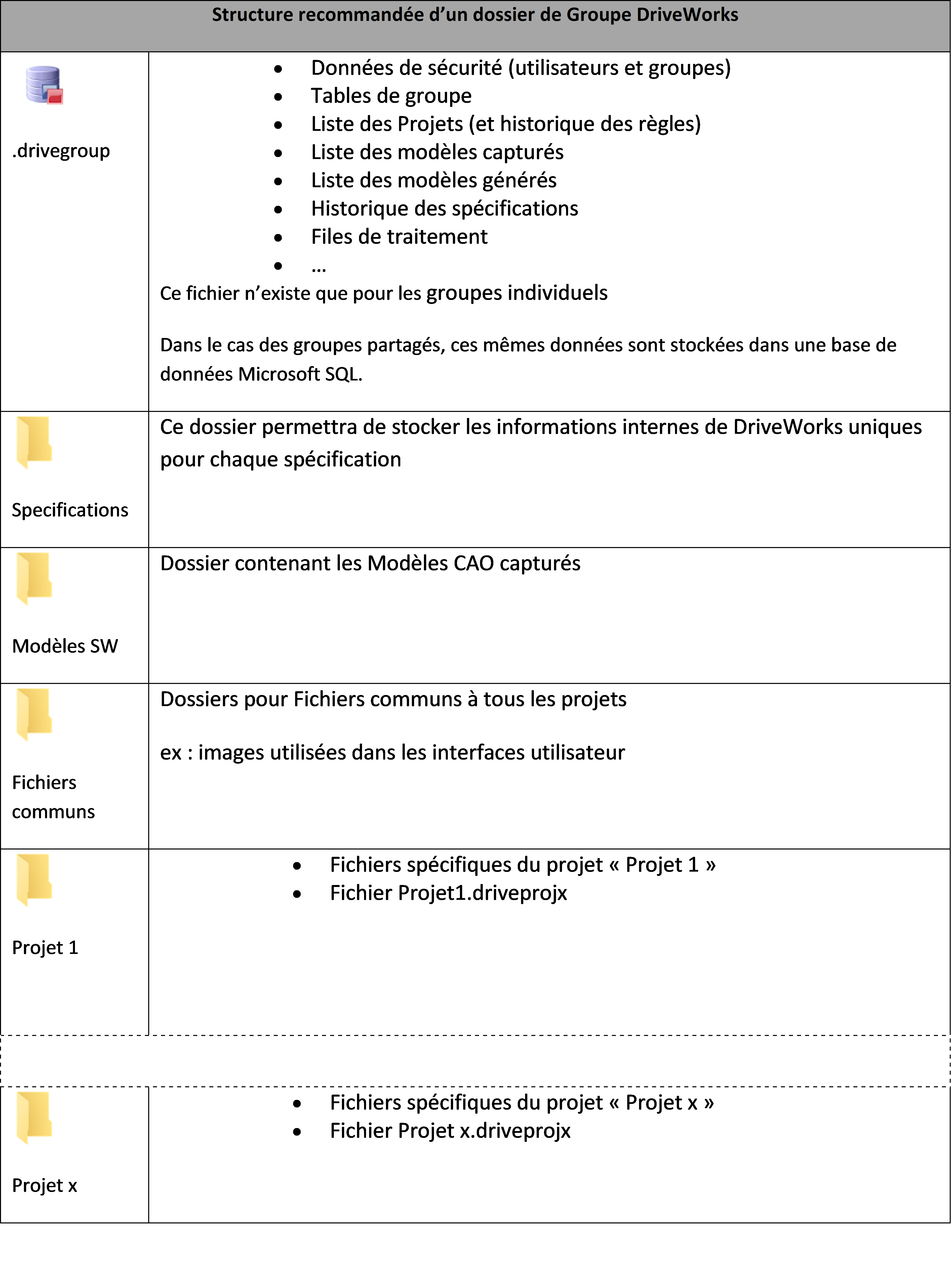
Le respect de cette structure vous assurera de pouvoir utiliser l’ensemble des outils de gestions de données de DriveWorks (DriveWorks Data Management Tools).
Si vous décidez de modifier cette structure (exemple : sauver vos projets directement dans le dossier du groupe), certains de ces outils pourront ne pas fonctionner correctement.
Les fichiers de production (SOLIDWORKS, Word, Excel, etc.), qui seront générés par DriveWorks lors de l’utilisation des configurateurs, peuvent, bien entendu, être stockés où vous voulez, indépendamment de cette structure si nécessaire.
Lors de la création d’une nouvelle spécification, DriveWorks stocke systématiquement une copie du projet utilisé ainsi que les données saisies par l’utilisateur. Afin de pouvoir rééditer ou traiter cette spécification par la suite, ces données doivent pouvoir être retrouvées sans risques de perte ou de conflit.
C’est dans le dossier Specifications contenu dans le dossier d’un groupe DriveWorks que seront stockées ces données internes à DriveWorks.
Pour éviter toute perte ou conflit de données, chaque Spécification doit avoir un identifiant unique et doit stocker ces informations dans un sous dossier du dossier Specifications, nommé en utilisant cet identifiant.
Les Child Specifications sont également concernées par cette nécessité de référence unique. Même si elles ne peuvent pas être ouvertes sans leur projet parent, elles sont également nommées avec un identifiant unique. Elles ont la particularité de ne pas générer de fichiers de données car ces informations sont encapsulées dans les fichiers de leur spécification parente.
Par défaut, chaque groupe DriveWorks dispose d’un compteur (SpecificationID). Il est utilisé comme identifiant unique pour toute nouvelle spécification.
S’il est possible de personnaliser le nom (Specification Name) et l’emplacement (Specification Path) de ces fichiers internes à DriveWorks, il faut impérativement s’assurer de l’unicité du nom et de l’emplacement de ces données pour chaque spécification.
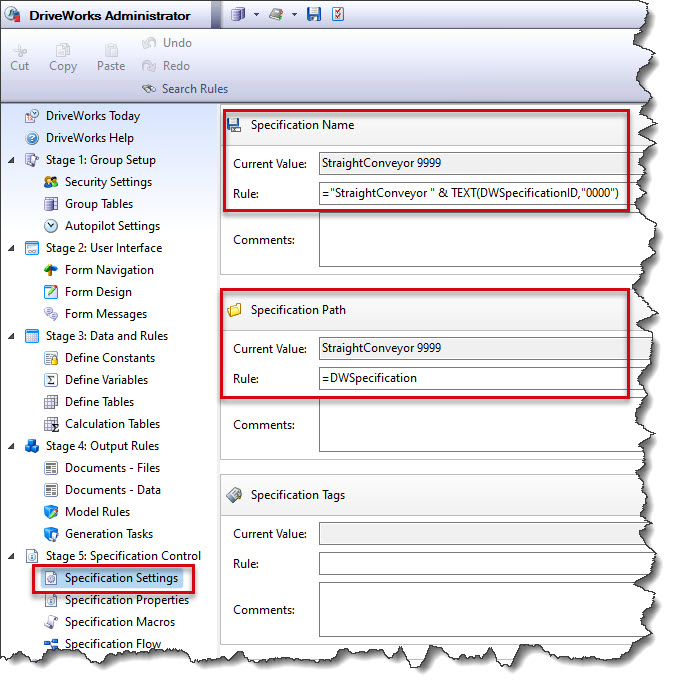
Il est donc souvent plus simple de ne pas modifier ces paramètres.
Dans un projet, tant que l’on n’aura pas personnalisé les règles par défaut, tous les fichiers que l’on prévoit de générer avec DriveWorks (pièces, assemblages, mises en plan, PDF, Word…) seront stockés en utilisant le nom unique de la spécification ainsi que l’emplacement des données internes de DriveWorks.
Lorsque l’on souhaite générer les fichiers SOLIDWORKS dans un dossier d’affaires sur le serveur de fichiers de l’entreprise, il est donc très tentant de modifier le dossier Specifications du groupe DriveWorks pour qu’il pointe vers ce dossier d’affaire. Ainsi, tous les fichiers générés par DriveWorks seront par défaut sauvés dans cet emplacement. Mais en procédant ainsi, les fichiers internes de DriveWorks le seront aussi.
La seule personnalisation de l’emplacement ne gênera qu’en cas de maintenance (per exemple pour supprimer les spécifications obsolètes).
Cependant, en plaçant les dossiers de spécifications dans un dossier d’affaire, la tentation est encore plus grande d’en profiter pour nommer ces dossiers en reprenant les standards en place dans l’entreprise. Et c’est ce nommage qui ne permet souvent pas l’unicité du nom de la spécification.
Parmi les cas courants, notons :
En cas de conflit ou perte de ces fichiers internes pour une spécification donnée, ses transitions et opérations deviendront alors indisponibles et la spécification ne sera plus éditable. Il ne faut donc pas procéder de cette façon !
A la place, nous vous conseillons de modifier les règles qui pilotent le nom et l’emplacement des fichiers à générer sans altérer les paramètres de ce dossier Specifications interne à DriveWorks.
S’il est évident qu’il faut nommer correctement une table, on oublie souvent qu’il faut en nommer correctement les colonnes. En effet, si dans DriveWorks on précise une colonne par son numéro d’index dans toutes les fonctions référençant une table, ce n’est pas pour autant une bonne habitude.
La relecture des règles utilisant des numéros de colonnes est complexe :
“ Qui se rappelle le rôle de la 42ème colonne d’une table 6 mois après ? „
De plus, il existe un risque d’erreurs important en cas de réorganisation de la table.
En référençant une colonne par son numéro d’index dans les règles, on court le risque de générer de très nombreuses erreurs dans tout le projet en changeant l’ordre des colonnes d’une table.
Une fonction spécifique existe dans DriveWorks pour éviter ces inconvénients :
– Elle permet de retrouver l’index de la colonne d’une table par son nom.
– Elle peut être utilisée directement dans les fonctions à la place de l’index de la colonne souhaitée.
Cependant, nous vous conseillons une approche plus systématique :
Ces règles seront toutes identiques à l’exception du nom de la table et de celui de la colonne.
Il serait donc assez simple de les générer dans Excel à partir d’une liste des nom de colonnes.
Astuce : il est possible de copier une ou plusieurs variables de DriveWorks vers une table Excel (et vis-versa ? )
Si ces opérations peuvent paraître longues à créer par rapport à l’utilisation directe des numéros d’index, ce temps est largement regagné dans la globalité de la vie d’un configurateur.
A chaque relecture d’une règle, il n’y aura plus de confusions ou de temps perdu à retrouver le rôle d’une colonne par son numéro. De plus, puisqu’il permet la réorganisation d’une table sans aucun risque, il participera à rendre vos projets DriveWorks plus robustes.
En plus de ne pas nommer les colonnes, il ne faut pas placer de valeurs directement à partir de la première ligne d’une table. En effet, la majorité des fonctions relatives aux tables ne liront pas cette ligne puisqu’elle est supposée contenir… les noms de colonnes.
Les tables de calculs fonctionnent d’une façon similaire à une feuille de calcul Excel.
Dans la règle de calcul d’une cellule, il est ainsi possible d’utiliser les valeurs des autres cellules de la table en les référençant de manière relative. C’est-à-dire en indiquant la direction et le nombre de cellules séparant la cellule actuelle de celle contenant la valeur voulue.
Exemple de syntaxe d’une référence relative :
Si cela est très pratique pour créer les règles nécessitant ce type de références, cela peut également se révéler problématique si on envisage de modifier l’ordre des colonnes après l’écriture des règles.
Par exemple, dans une table de trois colonnes : A, B, C et D

Si on réorganise la table pour avoir l’ordre suivant : C, A, B et D
Les valeurs de la colonne D sont alors très différentes

Cela représente un risque d’erreur si on n’est pas conscient de l’existence de cette règle et du danger potentiel de réordonner les colonnes d’une table de calcul.
Dans les tables de calculs, il est possible de référencer une cellule de 2 façons :
“ Il y a cependant une différence majeure par rapport à une table Excel qu’il faut connaître ! „
Une cellule de la table de calcul ne peut pas référencer la table en elle-même en dehors des deux types de références citées plus haut.
Cela s’explique simplement.
Dans ce cas, il faut simplement utiliser une seconde table de calcul pour interroger la première contenant les données souhaitées.
Il faut cependant garder en tête la complexité de calcul que ces tables peuvent représenter. Si elles contiennent beaucoup de cellules avec des règles complexes, ces tables peuvent assez vite demander beaucoup de ressources. Il convient donc de bien réfléchir à la structure des données pour ne pas multiplier ces règles complexes inutilement (ex : requêtes SQL, imports de fichiers…).
Pour calculer la longueur d’une pièce dans un assemblage, il est tentant d’utiliser, par exemple, la longueur hors tout saisie par l’utilisateur et les jeux fonctionnels directement dans la même règle.
« Que se passera-t-il le jour où il faudra modifier ce jeu fonctionnel ? Combien de règles utilisent ce jeu fonctionnel dans tout votre projet ? »
Il est également tentant, pour insérer une image dans l’interface, d’aller la chercher dans l’explorateur Windows pour ajouter le chemin à la règle pilotant cette image.
« Que se passera-t-il si le dossier est déplacé ? Combien d’images dans combien de pages de l’interface doivent être modifiées individuellement pour retrouver toutes les images d’origine ? »
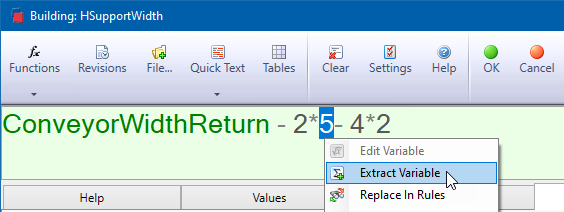
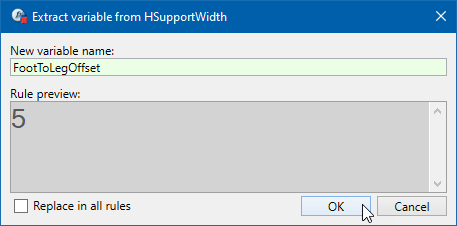
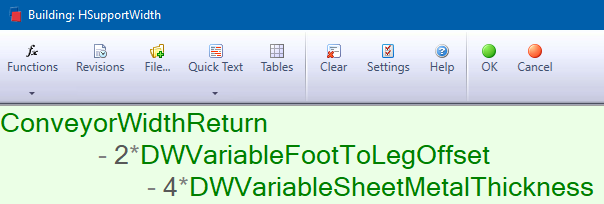
Exemple de règle, voici un cas inspiré du manuel de formation de DriveWorks Pro :
Mettez-vous en situation : 6 mois après avoir créé cette règle, vous arrivez devant cette règle, sans avoir le schéma…
« A quoi correspondent les chiffres dans la formule ? Et comment savoir dans quelles règles intervenir (en plus de celle-ci) le jour où certaines de ces valeurs changeront ? »
Que vous travailliez seul(e) ou en équipe sur des projets de configurateurs DriveWorks, il est important d’uniformiser le nommage des objets créés dans vos configurateurs.
Lors de l’ajout d’un objet dans DriveWorks, un nom est systématiquement demandé.
Pour cette raison, en plus de documenter vos projets de configurateurs pour pouvoir facilement les modifier plusieurs mois/années après leur création, il est important de bien réfléchir au nommage des entités et de toujours appliquer la même logique (surtout s’il y a plusieurs utilisateurs).
Voici une liste non exhaustive de conseils sur le nommage des entités DriveWorks :
Il est facile de retrouver une CheckBox parmi d’autre types de contrôles. Son type sera toujours affiché dans l’arbre des formulaires (il est possible de filtrer cet arbre par types).
En revanche, il sera beaucoup plus pratique de choisir un nom qui permettra rapidement de retrouver cette entité lorsque vous devrez la référencer dans une règle.
Exemple de filtre sur l’interface du projet du manuel de formation DriveWorks Pro :
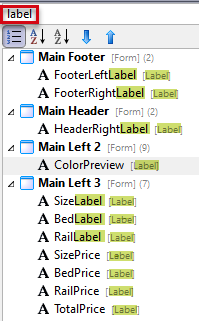
Par défaut, DriveWorks reprend le nom de l’entité pour l’utiliser dans le texte à afficher. Cependant, ce texte que l’on prévoit d’afficher présente souvent des inconvénients pour assurer un nommage clair, concis et unique d’une entité.
N’hésitez pas à choisir un nom qui vous facilitera la tâche en tant que concepteur du configurateur. Ensuite, vous pourrez personnaliser le texte à afficher à l’utilisateur pour que le rôle de cette entité soit clair.
Lorsque l’on copie/colle une entité nommée avec un suffixe numérique dans un même projet, DriveWorks incrémente automatiquement ce suffixe (sauf pour les noms trop courts = moins de 5 caractères, suffixe compris).
En préparant correctement la première entité (en utilisant notamment les fonctions MyName() et ExtractNumber() ), il devient possible de créer rapidement des dizaines d’entités sans avoir à retoucher les règles. Après la copie, chaque règle changera son comportement en “s’adaptant” au suffixe porté par le nom de l’entité.
Ce système de nommage peut aussi permettre la communication automatique avec les tables de calculs de DriveWorks (Control Input et Control Output).
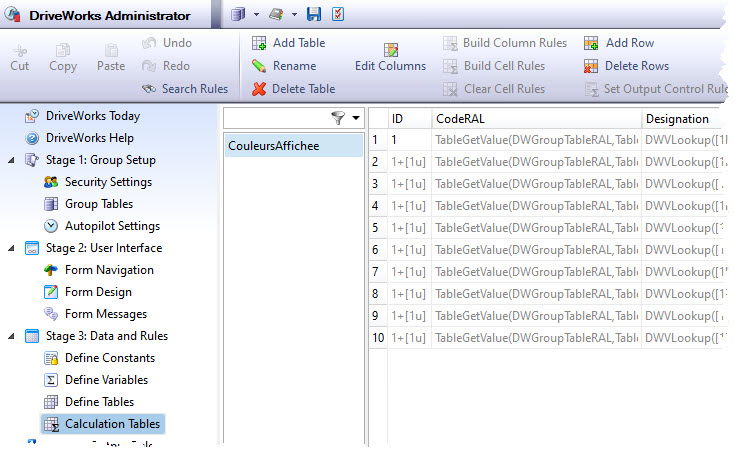
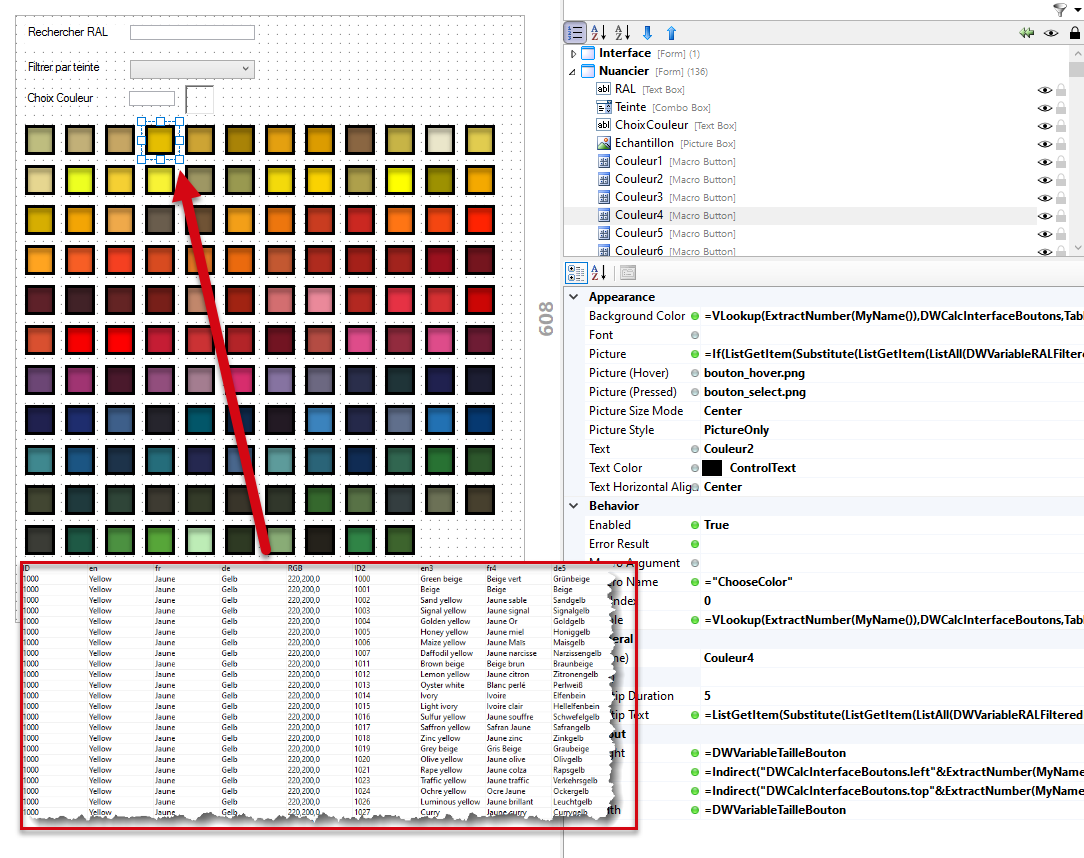
Exemple de projet de Nuancier RAL réalisé avec ce principe :
Ici toutes les vignettes ont été créées par copier-coller. Elles utilisent donc toutes les mêmes règles. C’est uniquement grâce au suffixe de la vignette que chaque règle ira chercher la bonne valeur dans les tables de la base de données.
Utilisées par les Child Specification controls : assurez-vous de nommer de manière claire les constantes ayant pour but d’être pilotées par un projet parent. N’hésitez pas à les copier depuis un projet terminé similaire pour éviter toute erreur dans des nouveaux projets (le copier-coller de constantes entre projets est possible).
C’est également le cas pour une utilisation par
Utilisées par des macros : n’hésitez pas à rappeler le nom de la macro dans laquelle elle est référencée (dans son nom ou sa description)
– Comme pour les entités de Form Design, l’utilisation de suffixes numériques peut permettre de créer/gérer des règles en masse si elle est bien pensée. Ces variables utiliseront généralement aussi les fonctions MyName() et ExtractNumber().
– Utilisez les catégories pour classer les variables.
Il est possible de créer autant de niveaux de sous-catégorie que nécessaire.
Il est même possible d’illustrer une catégorie en lui associant une image (schéma de principe…).
– Les variables peuvent avoir tous types d’entités comme résultat (nombre, texte, liste, table, booléen).
N’hésitez pas à indiquer dans le nom d’une variable le type d’entité qu’elle calcule. Ce sera plus simple de retrouver cette entité par la suite. Cela permettra également d’éviter d’utiliser une variable pour une autre dans une règle.
– Nommer toutes les colonnes des tables afin de pourvoir les référencer par leur nom à la place de leur index grâce à la fonction TableGetColumnIndexByName()
– Il n’est pas possible d’utiliser un suffixe numérique dans le nom de colonne d’une table de calcul.
En effet, la référence « Valeur12 » d’une colonne nommée « Valeur » indique la valeur à la 12ème ligne de cette colonne. Il est donc logique ne pas pouvoir également ajouter un suffixe numérique au nom de la table (c’est en revanche possible au milieu du nom).
– L’adresse d’un nœud dans un document Drive3D est référencé par un chemin similaire à une arborescence d’un disque dans Windows.
Comme pour les entités de Form Design, l’utilisation de suffixes numériques peut permettre de créer/gérer des règles en masse si elle est bien pensée. Ces variables utiliseront généralement aussi les fonctions MyName() et ExtractNumber().
Cela est facilité par l’option « View as combined » de la barre de commande. Elle regroupera toutes les propriétés de même nom des entités actuellement sélectionnées. Cela permet d’ajouter une règle sur l’ensemble des propriétés de toutes les entités actuellement cochées.
Pour éviter toute erreur, si une propriété affiche “…” comme résultat, alors que plusieurs entités sont sélectionnées avec l’option “View as combined”, c’est qu’au moins l’une des règles est différente.
Plus généralement et en complément du nommage des entités : utilisez les descriptions “en plus du nommage” pour préciser le rôle et le fonctionnement de certaines règles.
Lors de l’utilisation d’un configurateur, la spécification peut passer par plusieurs états (ou étapes). Ces états sont décrits par un synoptique appelé Specification Flow.
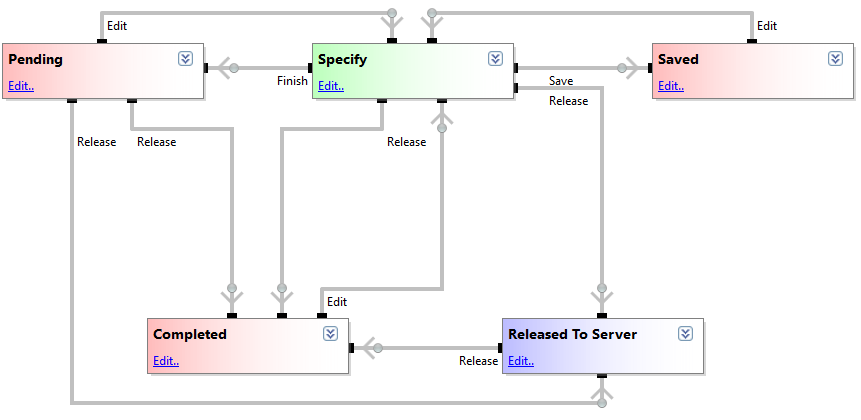
L’état actif lors de l’utilisation du configurateur par les utilisateurs est l’état Actif (Running). C’est dans cet état que le configurateur est ouvert et que l’interface utilisateur conçue dans DriveWorks Pro Administrator est affichée.
Cet état est accessible depuis toutes les interfaces permettant de lancer une spécification : depuis le Specification Explorer des applications DriveWorks ou depuis un navigateur internet connecté à un serveur DriveWorks Pro Live.
DriveWorks Pro Autopilot est le module chargé de centraliser les actions de génération ou les tâches dont on veut soulager les autres modules. Il est généralement chargé exclusivement de la génération des fichiers SOLIDWORKS, Word ou Excel (qui ne peuvent pas être générés par DriveWorks Pro Live directement).
Pour qu’un document arrive dans les files de traitements pour génération par Autopilot, il faut exécuter les tâches « Release Document » ou « Release Model ».
Cependant, suivant quelle application exécute ces tâches et quand la tâche est exécutée, le résultat peut varier.
Si la tâche est exécutée pendant que l’interface utilisateur est affichée (par une Specification Macro), c’est l’application depuis laquelle la Specification a été lancée qui se chargera de la traiter.
Cela peut avoir des conséquences sur les performances perçues par l’utilisateur. En effet, pendant le traitement par un serveur DriveWorks Pro Live, l’interface utilisateur peut être indisponible (“Loading” affiché).
Ce traitement peut même être impossible dans le cas d’un DriveWorks Pro Live hébergé sur un serveur Microsoft IIS. En effet, dans ce cas, les applications Word et Excel ne sont pas accessibles par un service. Ces deux types de documents ne peuvent donc pas être générés/lus/modifiés de cette manière.
Ce n’est donc pas de cette façon qu’il faut procéder pour que la génération de documents soit traitée par DriveWorks Pro Autopilot.
Ces tâches de génération peuvent aussi être exécutées plus tard dans le Specification flow (pour Autopilot):
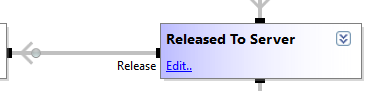
Ces état permettent de confier des actions à tout DriveWorks Pro Autopilot configuré pour traiter la file de traitement des Specifications (aussi chargée des documents).
Lors de la définition d’un état, il est possible de définir des tâches qui seront systématiquement exécutées à l’arrivée ou la sortie de cet état (il est possible d’ajouter des conditions à leur exécution).
Afin de confier la génération de documents à une machine DriveWorks Pro Autopilot, il faut donc que les tâches “Release Document” ou “Release Model” soient idéalement exécutées depuis le Specification Flow en sortie d’un état Automatic.
DriveWorks Pro Live peut fonctionner de 2 façons : en tant qu’application ou hébergé par un serveur Microsoft IIS.
Le fonctionnement en tant qu’application peut être suffisant pour des tests, ou dans les cas où il y a peu d’utilisateurs, ou encore qu’on ne souhaite pas une haute disponibilité et de bonnes performances.
Il est donc extrêmement courant d’utiliser l’hébergement par un serveur Microsoft IIS pour les configurateurs en production. Microsoft IIS fonctionne sous la forme d’un service Windows.
Un service sous Windows a la particularité de démarrer indépendamment des sessions utilisateurs.
De ce fait, un service n’a pas accès aux applications ou éléments de Windows qui démarrent avec une session utilisateur Windows.
Cela a plusieurs conséquences sur DriveWorks Pro Live lorsqu’il est hébergé de cette façon :
Ce dernier point peut paraître surprenant car nous avons l’habitude d’utiliser ces lecteurs qui sont souvent “montés” automatiquement à l’ouverture de nos sessions Windows en entreprise.
Le problème vient justement du fait que ces lecteurs existent uniquement pendant une session utilisateur. Un service ne peut donc pas simplement accéder à ces disques réseaux.
C’est pour cette raison qu’il ne faut pas utiliser ces chemins dans les projets DriveWorks lorsqu’une utilisation future de DriveWorks Pro Live avec Microsoft IIS est envisagée.
Il suffit, à la place, d’utiliser le chemin complet réseau permettant d’accéder aux fichiers souhaités (en passant par la machine les hébergeant dans le voisinage réseau).
Ces chemins complets sont aussi appelés chemins UNC (Uniform Naming convention ou Universal Naming Convention)
« Comme il est bon de garder le meilleur pour la fin, voici probablement le conseil le plus important de tous. C’est malheureusement celui qui est le plus souvent sous-estimé. Car s’il prend du temps à mettre en place, il peut aussi vous éviter d’en perdre énormément ! »
Il est capital de documenter vos projets de configurateurs pour pouvoir facilement les modifier plusieurs mois/années après leur création par vous et encore plus par un autre collaborateur. Le document de description de chaque projet est probablement le plus important à rédiger.
Ce document devrait par exemple idéalement détailler :
Une fois en production, il est conseillé également de conserver un historique détaillé des modifications réalisées sur le configurateur et de leur raison/origine. Les outils permettant un tel suivi sont très variables suivant vos habitudes ou suivant si vous travaillez seul ou en équipe.
Par expérience, voici quelques supports fréquemment utilisés et assez efficaces :
« Voyez donc la documentation comme un investissement comparable à une assurance : il est techniquement possible d’habiter un logement sans assurance pendant des années sans gêne particulière. Mais le jour ou un problème survient… Mieux vaut être assuré ! »
Réduisez vos délais de conception avec un configurateur CAO créant les variantes de vos produits standards en quelques minutes.
DécouvrirSimplifiez et accélérez vos processus de vente et de fabrication de vos produits complexes.
DécouvrirBénéficiez d'une solution de conception et de fabrication intuitive, puissante et novatrice pour transformer vos idées en produits innovants.
Découvrir
Inscrivez-vous à nos Newsletters
En savoir plus sur
![]()